Method
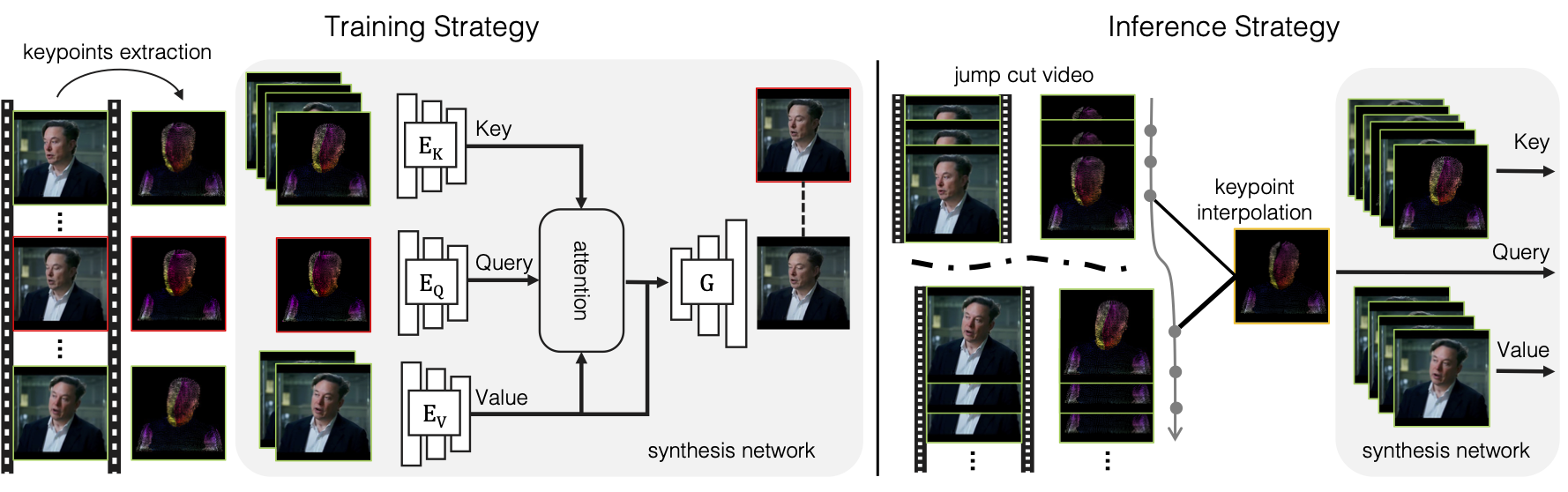
In the training stage, we randomly sample source (denoted in green rectangle) and target (denoted in red rectangle) frames, and extract their corresponding DensePose keypoints augmented with facial landmarks (not shown here for simplicity). Our method extracts source dense keypoint features as key, target dense keypoint feature as query, and source image features as valye, then a cross attention is applied to get the values for the query, i.e., warped feature. This warped feature is fed into the generator inspired from Co-Mod GAN to synthesize a realistic target image compared with the ground truth target frame. For applying jump cut smoothing in the inference stage, we interpolate dense keypoints between jump cut end frames, and synthesize the transition frame with the interpolated keypoints (in yellow rectangle) sequence.



